Closing the (IoT) Loop with Control and Analytics (Software Stack @ Zenatix, Part-2)
Continuing on my series of write-ups to give a deeper perspective into the technology stack at Zenatix, this is the second one in the Software vertical.
For more context and details about the first version of our technology stack (in place in the initial couple of years), please refer to Evolution of IoT Stack @ Zenatix. I would also highly recommend reading the first one before continuing on this one. In this, I will be covering up the transition over the next 2–3 years after the initial stack was in place.
First up — while I am talking about the next version of the IoT stack at Zenatix in this blog, these transitions do not happen overnight. It all depends on some conscious calls and sticking to those calls over months and years to achieve what you set forth for in the beginning. As a result,
one has to patiently build things, balancing the short term business requirements (that will and should always remain at higher priority) with longer term stack transitions.
This patience is all the more important (and in fact all the more difficult to practice) when you are working with a lean and young technology team. As a result, team composition becomes important. You need folks (or groom such folks when you have the energy around but not the experience) who can take the pressure that comes with this balancing act. And the credit should go to such folks — who raise their hands, bring the passion, do the necessary research to jointly conceive how the technology stack should improve and put in a lot more effort than what a regular employee would. As a company, you should be cognisant of the effort put in by such folks and reward them appropriately by recognising them in different ways possible.
Priorities in the tech stack have to follow where the business is going.
As we started working on IoT in Built Environment, and narrowing down to small (and distributed) built environment (e.g. retail chains), a few things became important.
- Closing the loop with automated control — End customer would not pay for the data but will pay for the outcome. Early on, we tried getting that outcome in terms of only data analytics (and I see many companies in the IoT space still doing that mistake). We would analytically estimate the cooling rate of the building to decide what is the right time to switch on and off different components of the Air Conditioning (or HVAC as it is commonly referred to) system. However, since the systems continued to get controlled manually, our complex analytics would often go to waste since the person (who is responsible to take the action) does not act on the notification given by the system. We were convinced that if we have to deliver real outcome (and savings was the most lucrative outcome), we have to start controlling the systems automatically as well and remove the man-in-the-middle wherever possible.
- Analytical framework — While control’s importance was well established, with a lot of data collection we also realised that there are low hanging fruits in doing simple computations on this collected data to generate actionable outcomes. As an example, convert raw temperature data from a cold room collected throughout the day into percentage of time during the day when cold room temperature was not within compliance range. Such cold rooms (from 100s spread across the stores) can then be reported for checking by the on-field technicians (making these technicians more efficient).
- Automated identification of hardware failure in the field — Since our target segment was narrowed down to retail, we knew that we would be installing a lot of hardware in a distributed manner (as of date, our system is deployed across 200+ cities in India). So it is important that we are able to maintain/service this geographically distributed hardware in a scalable manner.
The first requirement was served by developing an end to end pipeline for automatically controlling the devices at the customer site (based on time, sensor values etc.).
Over time, this control has become a key differentiator for us. This is what ensures that the customer gets the real benefits (in terms of energy savings) from the IoT systems that we retrofit.
This end to end Control consisted of multiple services (each serving their own purpose):
- A service running on the edge which ensured that the control happens even if the gateway is disconnected from the cloud. Unlike sensor data (even if you loose some data, it is not such a big deal), control is critical. This edge service takes intelligent decisions to ensure appropriate control happens at the right time. Over time, we made many advancements in this edge control service adding — switching off the contactor relays (to avoid the coils getting burnt) when the voltage levels go below a certain threshold (as discussed in my previous post — these thresholds have been decided intelligently based on the collected data and instances of contactor coils getting burnt for our systems); prioritising between sensor based control, time based schedules and instant (manual) control; supporting an over-ride duration when performing instant control; adding an over-ride button in our hardware which allows for manual extensions of schedules when the system is offline and supporting a mobile based application which can perform control on our local WiFi network in the store (besides performing it over network) during the times when system is offline, among others. For all of this intelligence, our earlier decision of going with a processor based edge system had come in handy.
- Device shadow service in the cloud (in today’s world its also termed as device twin or device clone) — This served as a virtual gateway on the cloud. Any configurations (including control configurations) that are to be passed on to the edge are simply passed on the device shadow and then it is the responsibility of this service to sync it across all the field gateways (as and when they come online). As a result, the work for any service in the cloud that has to communicate to the edge was cutout — simply communicate with the shadow and the shadow will sync with the edge. Furthermore, since the configurations were always stored in the cloud, when the edge hardware was to be replaced (or the SD card hosting the OS got corrupted), it was much easier to restore it to its last configuration. Over time, we have addressed several complications in this Device Shadow service — deciding the source of truth when the edge and the cloud configurations are in-conflict; maintaining different versions of the configurations with an ability to restore older versions, if required, and supporting notifications when undesired configuration is returned from the edge, among others.
- Control service — This was the backend which routed different control configurations/actions to the device shadow. Different user inputs, such as an excel file (on which several validations are to be done) or a button on the frontend or a Google Sheet where account managers would configure different types of sensor based control, were passed on to this backend service. This backend is where the business logics (that addressed several corner cases) were coded. As an example, if a load is left ON and there is no OFF time during the day then a warning (to someone who is doing the configuration) is raised. Another example is schedule expiry — when we set time based schedules, an expiry date is associated with them (for several business reasons). When this expiry date is coming closer, an appropriate notification is raised by this service.
This end to end control architecture was supported by different user interfaces (a csv upload, a Google spreadsheet, a web dashboard and a mobile app) to address different (both internal and external) business requirements.
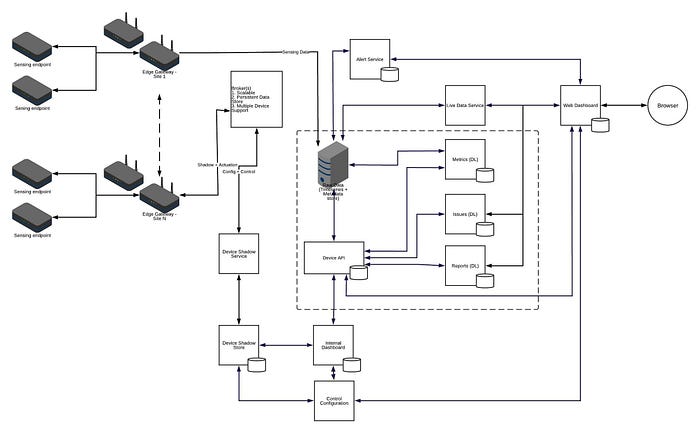
Besides control, an analytical framework to extract actionable insights from the collected data made perfect sense to create business value.
Early on, we realised that a lot of actionable insights (internally termed as metrics) can be achieved through not-so-complex models (which over time started becoming more and more complex too).
As a result, we needed a framework (we internally call it metrics framework) using which the analytics team can write these simple models and the framework would ensure that these models are run appropriately. These metrics (or one can call them as computed streams) are then stored back in the timeseries DB and thus are treated as timeseries data by other parts of the stack. As a simplified analogy, one may consider this metrics framework as similar to AWS IoT Events framework. To address them appropriately, this framework supported several features:
- Configuring the time when these metrics should be computed — As is obvious, unlike high frequency raw data (which we collect at sub-minute level), metrics make sense at lower frequency i.e. daily/hourly. This scheduling was initially done using cron but we faced several issues specifically related to reporting of failures when these crons would fail to run (either because of a problem in the framework or problem in the encoded models). We have over time moved these to Airflow DAGs.
- Another important thing that this framework decides is if there is sufficient data to compute a specific metric. Since IoT devices may be disconnected at times or sending buffered data at other times, it is important to keep a tab on when to compute a metric depending on the data availability and from which time re-compute it, when we run it subsequently.
- Backfilling — Often when a new metric is coded, it has to be applied on historical data as well to give a historical view to the end customer. The framework was built in a way that made calculating metrics on the last day very efficient. As a result, this requirement of backfilling a new metric on historical data has to be dealt with in a separate way.
Since the metrics framework takes care of these complexities, the analytics team simply have to code their logic and the framework takes care of the rest of the infrastructure stuff that is common across all metrics.
Besides generating value from the collected data for the end customer using the metrics framework, we also derived value from the collected data (specifically the collected health information) to help us maintain the deployed systems efficiently.
As we were deploying more and more hardware, we wanted to ensure that our own hardware is performing well in the field. This notion ran deep inside the tech team. As a result, every new hardware that we introduced provided a lot of health information in addition to the application data. As an example, the WiFi temperature sensor that we built provided several health metrics such as reboot counter, RSSI, reconnection counter, sensor error counter, uptime, software version, hardware version etc. We then started developing an automated engine at the cloud side (internally called as Issue Framework) that analyses these health metrics and creates actionable tickets for our troubleshooting team. Besides, we also developed automated tests (based on these health information) which were run at the time of deployment and ensured that the way installation is done is good enough and will last over time. The installation engineer can not leave the site until all the tests are passed on the application. Thresholds and logics for these tests were again intelligently decided based on the historical data that we had collected and over time, tuned to give more efficiency in terms of actionable insights generated from the data. As one example, if all the (WiFi based) temperature sensors are not sending data from one site, the ticket is raised for the WiFi router and not for each of the temperature sensors.
This system of automated issue reporting has also helped us improve our offering — hardware was subjected to many real world scenarios that resulted in failures when certain corner cases were not addressed. Each failure encounter which the troubleshooting team could not resolve with the standard process was reported back to the technology team which was then used to address many new corner cases and do remote firmware over the air updates. This direction of using technology to proactively (and in an automated fashion) identify the problems during and after installation, was the third important thing we did to close the loop with the data and has helped us scale to 2500+ deployments, served with a very small size troubleshooting and deployment team.
This is something that any OEM should take inspiration from — if they can connect their devices installed in the field and automatically analyse the health information, they can, not only optimise their field workforce (for maintenance) but also collect valuable data which can improve their product offering over time and give them a differentiator compared to their competitor.
The architecture as it evolved with the end-to-end control support, metrics and issues framework is shown in the Figure above.
All this while (though the initial 4-5 years of our existence) we created a monolith which was becoming more and more complex over time (and hence difficult to maintain). I will discuss about our decision to break this monolith into a service oriented architecture and new feature additions in our Software stack (over the next 2 years of our journey) in the my next and final post in the Software vertical.
